-
deep learning 기초 정리AI Basic 2023. 9. 13. 01:41
아래 예를 통해서 deep learning 기초를 배워보자!
책이서 배웠던 내용을 하나하나 짧은 시간에 실습하면 익힐 수 있어서 참 좋다.
https://github.com/karpathy/lecun1989-repro/
GitHub - karpathy/lecun1989-repro: Reproducing Yann LeCun 1989 paper "Backpropagation Applied to Handwritten Zip Code Recognitio
Reproducing Yann LeCun 1989 paper "Backpropagation Applied to Handwritten Zip Code Recognition", to my knowledge the earliest real-world application of a neural net trained with backpropa...
github.com
33 년에 적은 논문을 기반으로 andrej kapathy가 재현을 했고
아래와 같은 결과를 얻었다.
23 eval: split train. loss 3.879529e-03. error 0.60%. misses: 44 eval: split test . loss 2.824366e-02. error 4.19%. misses: 84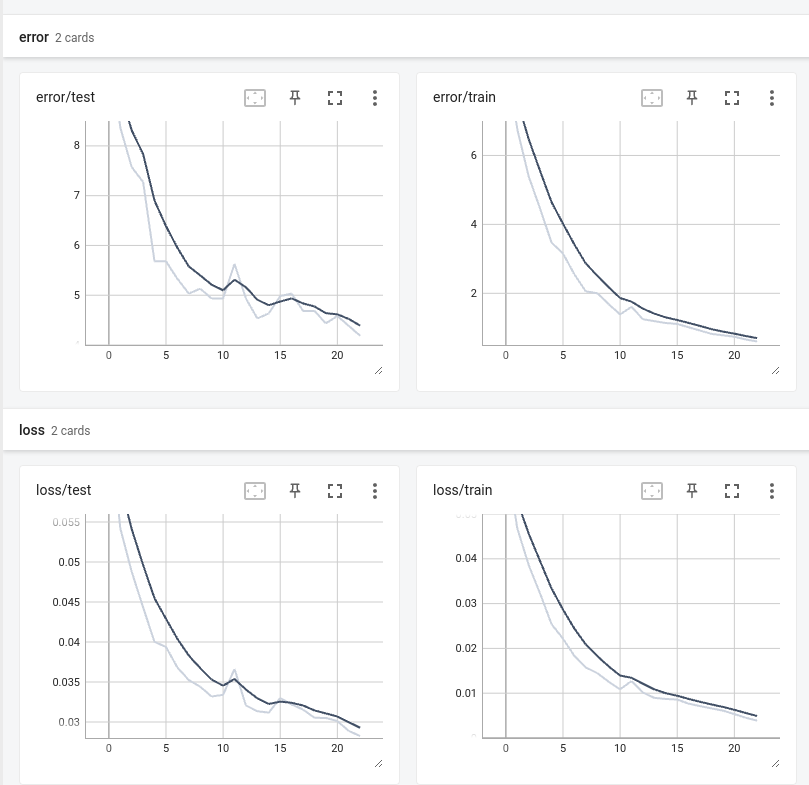
1.
x = torch.tanh(x) --> x = torch.relu(x)
만 변경해보자
맨 마지막은 변경하지 않는것을 잊지 말자!
별로 성능향상이 크지 않는 것을 알 수 있다. relu 자체가 gradient vanishing을 없애기 위해서 도입된것을 생각해보면 당연한 이치이다. 네트워크가 크지 않으므로 vanishing 될것이 없다.
23 eval: split train. loss 1.838940e-02. error 0.93%. misses: 67 eval: split test . loss 3.550898e-02. error 3.84%. misses: 77
2.
SDG --> adamW 으로 변경
stochastic gradient descent 설명
SGD: stochastic gradient descent (확률적 경사 하강법)
### 정의 확률적 경사 하강법(SGD: Stochastic Gradient Descent)는 머신러닝, 특히 딥러닝에서 사용되는 가장 대표적인 최적화 알고리듬이다. 전체 데이…
wikidocs.net
adam의 변형으로
Adam
파이토치에서 제공하는 Adam은 Adam(Adaptive Moment Estimation) 현재 가장 널리 사용되는 옵티마이저로, 이전 그래디언트의 지수적인 이동 평균을 사용하여…
wikidocs.net
AdamW
torch.optim.AdamW는 AdamW (Adam with Weight Decay) 옵티마이저의 구현체로, 파이토치에서 제공되는 옵티마이저 중 하나입니다. AdamW는 Ad…
wikidocs.net
https://hiddenbeginner.github.io/deeplearning/paperreview/2019/12/29/paper_review_AdamW.html
[논문 리뷰] AdamW에 대해 알아보자! Decoupled weight decay regularization 논문 리뷰(1)
재야의 숨은 고수가 되고 싶은 초심자
hiddenbeginner.github.io
사실 요즘 다 adam을 사용하므로 그냥 외우는것도 하나의 방법인것 같기는하다.
중요한것이 더 많다.~~~~
23 eval: split train. loss 0.000000e+00. error 0.45%. misses: 32 eval: split test . loss 0.000000e+00. error 3.94%. misses: 79
3. learning rate을 순차적으로 변경
아래와 같은 코드를 추가함.
alpha = pass_num / 22 for g in optimizer.param_groups: g['lr'] = (1 - alpha) * args.learning_rate + alpha * (args.learning_rate / 3)andrej kapathy쓴 블로그에서는 error가 0%로 떨어지는데 난 뭘 덜 수정했는지 그렇게 되지는 않았음.
그래도 error율이 감소함. learning rate 을 이렇게 순차적으로 3e-4 --> 1e-4로 줄여서하는것이 성능향상에 도움이 됨을 확인.
23 eval: split train. loss 0.000000e+00. error 0.14%. misses: 10 eval: split test . loss 0.000000e+00. error 3.24%. misses: 644. dropout 추가
andrej kapathy는 매개변수가 가장 많은 H3 앞에 넣고 0.25정도의 약한 drop out을 걸었다고 말고 있다.
당연히 훈련중에만 동작하고 eval중에는 동작하지 않는다.
x = F.dropout(x, p=0.25, training=self.training)성능이 더 안 좋아 졌다. 단 loss 값이 예전처럼 0%아니게 되었다.
아마도 횟수를 더 늘려야 할것 같다 blog에서도 더 많은 noise가 발생하므로 훈련량을 늘렸다는 얘기가 있다.
23 eval: split train. loss 2.396078e-05. error 0.60%. misses: 44 eval: split test . loss 2.396078e-05. error 3.44%. misses: 695. agumentation 추가
위에 dropout했던것을 우선 disable 하고 3번 에서 agumentation 만 추가했다.
if self.training: shift_x, shift_y = np.random.randint(-1, 2, size=2) x = torch.roll(x, (shift_x, shift_y), (2, 3))이미지를 shift시키는 것이다.
23 eval: split train. loss 1.668916e-05. error 1.98%. misses: 143 eval: split test . loss 1.668916e-05. error 2.69%. misses: 53확실히 성능이 좋아 진것을 알수있다.
여기서 알수 있는것은 훈련 error 값이 작다고 eval error 값이 꼭 작지는 않다는 것이다.
즉 훈련할때 과 적합이 일어났는지 아닌지 확인해야 한다는 의미이다.
이 결과에서 drop out을 추가하면
23 eval: split train. loss 4.294189e-04. error 2.43%. misses: 177 eval: split test . loss 4.294189e-04. error 2.49%. misses: 49약간 더 개선 된것을 확인 할 수 있다. 그러나 agumentation영향이 큰것을 확인 할 수 있다.
6. 훈련 횟수를 80으로 늘린다.
그러나 33년전 코드를 실행하면 아무리 실행해도 4% 언저리에서 머물고 있는것을 확인 할 수 있다.
57 eval: split train. loss 2.146069e-03. error 0.45%. misses: 32 eval: split test . loss 2.735095e-02. error 3.94%. misses: 79그러나 5번 코드를 71번만 해도 안정적으로 1.x%에 들어온다.
57 eval: split train. loss 1.716599e-05. error 1.62%. misses: 118 eval: split test . loss 1.716599e-05. error 1.84%. misses: 37 71 eval: split train. loss 3.576278e-07. error 1.39%. misses: 100 eval: split test . loss 3.576278e-07. error 1.59%. misses: 32이것을 통해서 모델 중요함을 알 수 있다. 나쁜 모델은 아무리 훈련해도 좋아지지 않는다.
위 예가 andrej kapathy가 개선한 내용들이다. 참 똑똑하다. 위 예들은 inference 시간을 증가키시지 않는 요인들이다. 즉 33년 전 논문에서 훈련시간 등은 길어 졌지만 inference 에는 다 동작 안 하는 기능들이므로 실행 시간은 똑 같다.
블로그에서도 더 좋은 모델을 사용하면 에러율을 낮출 수 있지만 그럴 경우 실행시간이 길어지는 단점이 있다.
그러나 위 경우 훈련시간만 길어질뿐 실제 실행시간은 길어지지 않는다.
그리고 잘 몰라도 데이터만 많이 하면 성능이 좋아는 예도 있다. 모두 다 아는 것이지만 말이아닌 데이터 확인하면서 보는 이것이 주는 insight는 참 큰것 같다.
반응형'AI Basic' 카테고리의 다른 글
python 기초 정리 (2) 2023.09.11 심층 신경망: 33년 전과 지금 33년(by Andrej Karpathy) (2) 2023.09.03 yolov5 모델로 보행자 사람 자전거만 탐지하기/검증파일 실행해보기. (1) 2023.03.22 yolov5 실행하기 (0) 2023.03.18 Transfer Learning Tutorial(전이학습) (0) 2023.03.12